How the Agentic Harness Works
SignalPilot is built on 4 foundational systems that work together to enable AI agents for data investigation — while keeping analysts in control.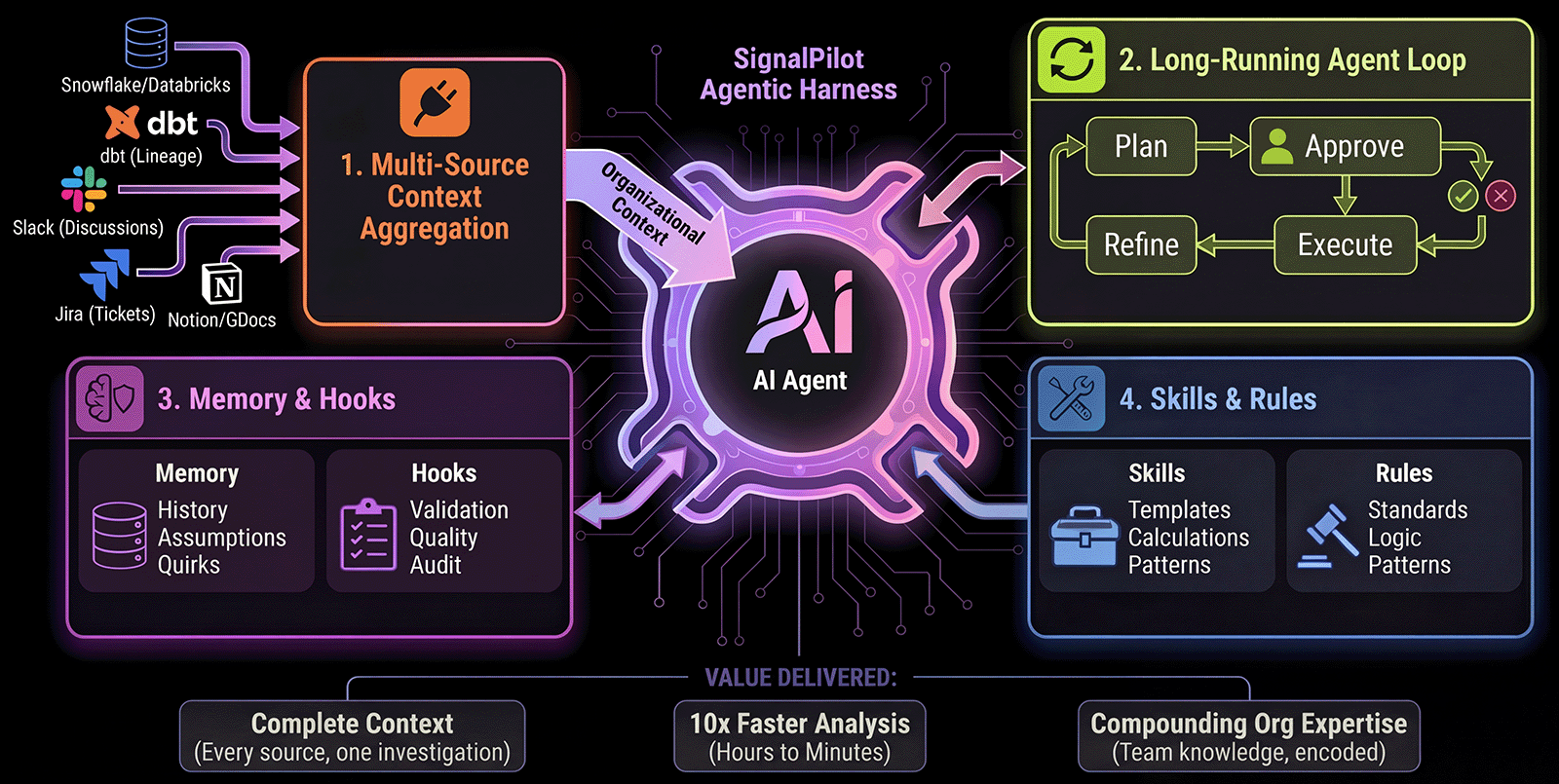
Four Foundational Systems
1. Multi-Source Context Aggregation
1. Multi-Source Context Aggregation
SignalPilot connects to your data stack via internal explorer and context orchestraton tools, jupyter notebook interface, and MCP (Model Context Protocol):Internal Context Explorer:
- Kernel operations (execute code, introspect state)
- Database queries (schemas, performance, history)
- Schema introspection (metadata, lineage)
- Kernel variables (dataframes, active data)
- Local files (notebooks, CSVs, configs)
- dbt (Cloud/Core): Model lineage, documentation, tests
- Slack: Threads, decisions, discussions about data
- Jira: Tickets, issues, deployment history
- GDocs/Notion: Design docs, wikis, runbooks
- Snowflake/Databricks: Query logs, usage stats
Deep Dive: MCP Architecture
Understand how MCP enables context orchestration
2. Long-Running Agent Loop (with Analyst-in-the-Loop)
2. Long-Running Agent Loop (with Analyst-in-the-Loop)
Unlike single-shot completions (ChatGPT) or auto-apply copilots, SignalPilot runs a long-running investigation loop with human oversight:Why “long-running”? Data investigations aren’t single queries — they’re multi-step processes. SignalPilot maintains context across the entire investigation.Why “analyst-in-the-loop”? You approve plans before execution. AI proposes, you decide. Full control with AI assistance.
Deep Dive: Agent Loop Mechanics
How the production loop works internally
3. Multi-Session Memory & Control Hooks
3. Multi-Session Memory & Control Hooks
Multi-Session Memory is the institutional knowledge layer that makes AI agents actually useful:
Control Hooks are safety guardrails that enforce governance and best practices:
- Analysis history: What hypotheses were tested in past investigations? What was ruled out?
- Validated assumptions: “Revenue calculation uses net, not gross” (learned once, applied forever)
- Known data quirks: “Orders table has duplicates before 2024-01” (no more rediscovering issues)
- Past solutions: “Last time conversion spiked, it was timezone issues” (pattern recognition)
Control Hooks are safety guardrails that enforce governance and best practices:
- Pre-execution validation: “Only query prod DB during office hours” (prevent accidents)
- Data quality checks: “Warn if row count changed >20%” (catch anomalies early)
- Custom constraints: “Always use vectorized pandas, never iterrows()” (enforce performance patterns)
- Audit logging: Track what data was accessed, when, and for what investigation (compliance-ready)
Deep Dive: Memory System
How memory works and what gets stored
Deep Dive: Hooks System
Custom constraints and validations
4. Skills and Rules System (Team Customization)
4. Skills and Rules System (Team Customization)
Custom Skills are reusable analysis patterns that encode your team’s domain expertise:
Rules are the coding standards and business logic that ensure consistency:
- Analysis templates: “Run cohort retention on users table with our 7-day/30-day windows”
- Domain calculations: “Calculate MRR using our billing logic: (seats × price) + overages - credits”
- Data transformations: “Clean customer addresses using USPS standards + international normalization”
- Visualization templates: “Generate exec-ready revenue waterfall using company brand colors”
Rules are the coding standards and business logic that ensure consistency:
- Code style: “Always import pandas as pd, use type hints, docstrings for functions >10 lines”
- Performance patterns: “Use vectorized operations, never .iterrows(), always explain() queries before large scans”
- Business logic: “Revenue = (price × quantity) - discounts, EXCLUDE test_accounts and internal domains”
- Data quality gates: “Flag if nulls >5%, dates outside [2020, today], or row count Δ >20%”
Deep Dive: Custom Skills
Build reusable analysis patterns
Deep Dive: Rules System
Enforce standards and business logic
Why These 4 Systems Make an “Agentic Harness”
The harness metaphor is intentional — just like a climbing harness provides infrastructure that keeps you safe while enabling you to climb higher, SignalPilot provides the infrastructure that lets AI agents work on complex data investigations while keeping analysts in control:- Context Layer (MCP) → Gives AI the organizational knowledge to reason effectively
- Long-Running Loop → Enables multi-step investigations (not single-shot queries) with human oversight
- Memory & Hooks → Learns from past work + enforces safety boundaries
- Skills & Rules → Customizes to your domain + coding standards
Real-World Example: All 4 Systems Working Together
Scenario: Your CFO asks “Why did our conversion rate drop 8% last week?”Traditional Workflow (2+ hours, no institutional knowledge capture)
- ⏱️ Open Snowflake, manually explore tables (no context)
- ⏱️ Copy schema to ChatGPT, ask for query (hallucinated table names)
- ⏱️ Run query, fix errors, re-run (3-4 iterations)
- ⏱️ Check Slack for recent changes (scroll back 100+ messages manually)
- ⏱️ Find Jira ticket about A/B test, read linked doc (manual search)
- ⏱️ Write new queries based on findings (no memory of what was tested)
- ⏱️ Create visualization in notebook (generic, not following team standards)
- ⏱️ Write summary, forget to document assumptions for next time
SignalPilot Agentic Harness (10 minutes, with learning)
Ask once: “Why did conversion rate drop 8% last week?” SignalPilot orchestrates using all 4 systems:1. 🔌 Context Aggregation (System 1)
- Fetches Snowflake schema (conversion_rate table, relationships)
- Loads dbt lineage (upstream dependencies: events → sessions → conversions)
- Searches Slack for “conversion” mentions last week → finds A/B test thread
- Pulls Jira ticket #3421 about experiment + linked design doc
- Queries Snowflake query_history for anomalies
2. 🔄 Long-Running Loop (System 2)
- Generates investigation plan: “Check A/B test deployment → Compare cohorts → Analyze funnel drop-off”
- 👤 Shows you plan for approval (analyst-in-the-loop)
- You approve → Executes in phases:
- Phase 1: Validate A/B test started on drop date ✓
- Phase 2: Compare treatment vs control conversion ✓
- Phase 3: Identify funnel stage with issue ✓
3. 🧠 Memory & Hooks (System 3)
- Memory recalls: “Last time conversion dropped (2 months ago), it was timezone bug in tracking”
- Checks that pattern first → Not the issue this time
- Hooks enforce: Data quality check flags that test group has 18% fewer users than control (suspicious)
- Saves to memory: “Conversion drops often correlate with A/B tests — check experiment metadata first”
4. 💻 Skills & Rules (System 4)
- Applies team skill: “conversion_funnel_analysis” (your pre-built analysis template)
- Follows rules: Uses vectorized pandas (not loops), excludes test_accounts, generates waterfall chart with brand colors
- Enforces business logic: Revenue calculation follows your formula (excludes refunds, includes discounts)
Outcome
- ✅ Root cause identified: A/B test deployed with buggy tracking pixel
- ✅ Before/after comparison chart (following team viz standards)
- ✅ Institutional knowledge captured: “Check A/B test experiments first for conversion anomalies”
- ✅ Next analyst who investigates conversion gets this pattern automatically
Try the Full Tutorial
Debug a revenue drop in 5 minutes (step-by-step)
Next Steps
Why SignalPilot?
See full comparison vs ChatGPT and IDE copilots
Security & Privacy
Read-only access, zero retention, audit trail
Quickstart Tutorial
5-minute walkthrough with your data
Key Concepts
Understand agents, modes, planning, and context