
Your Notebook
Doesn't Need More AI
Just Better Context
AI Copilots Fails Your Tasks, Ignoring Your
SignalPilot unifies your context and
Ships Python & SQL that Actually Runs
Built by and for people who live in notebooks
Data scientists, ML & Analytics Engineers, Quants, Researchers, and Technical Founders




Most AI Agents Waste Your Time
Without understanding your data stack and notebook state, AI agents create more problems than they solve
IDE Agents don't know your data resulting in hallucinated tables, columns, and join keys that don't exist
"Quick questions" from product, growth, or sales turn into hours of wiring, cleaning, and schema archaeology
You debug AI generated code instead of running actual backtests, experiments, and analyses
Product ML & quant work stalls because AI ignores your repo & library versions
Stop debugging hallucinations. Start building with confidence.
Built for Data Teams that Ship
Context-aware AI that understands your environment, plans ahead, and delivers production-ready insights.
Plan & code accurately
Generate multi-step plans with explicit assumptions, tables, and filters before writing code
Create environment-aware Python and SQL that respects installed libraries, versions, and organizational rules
Leverage notebook state to continue from existing variables instead of redefining everything
Understand your data and code
Scan warehouses and databases to use real models, columns, and contracts in queries and joins
Read local repositories and helper files to call functions with correct arguments and return types
Visualize & interpret
Create high-fidelity plots including complex layouts like facets, multi-axis charts, and small multiples
Generate concise interpretations that highlight trends, outliers, and key insights for decision-makers
Ship results
Publish lightweight dashboards from selected cells and plots for stakeholders
Share insights without requiring notebook access or technical expertise
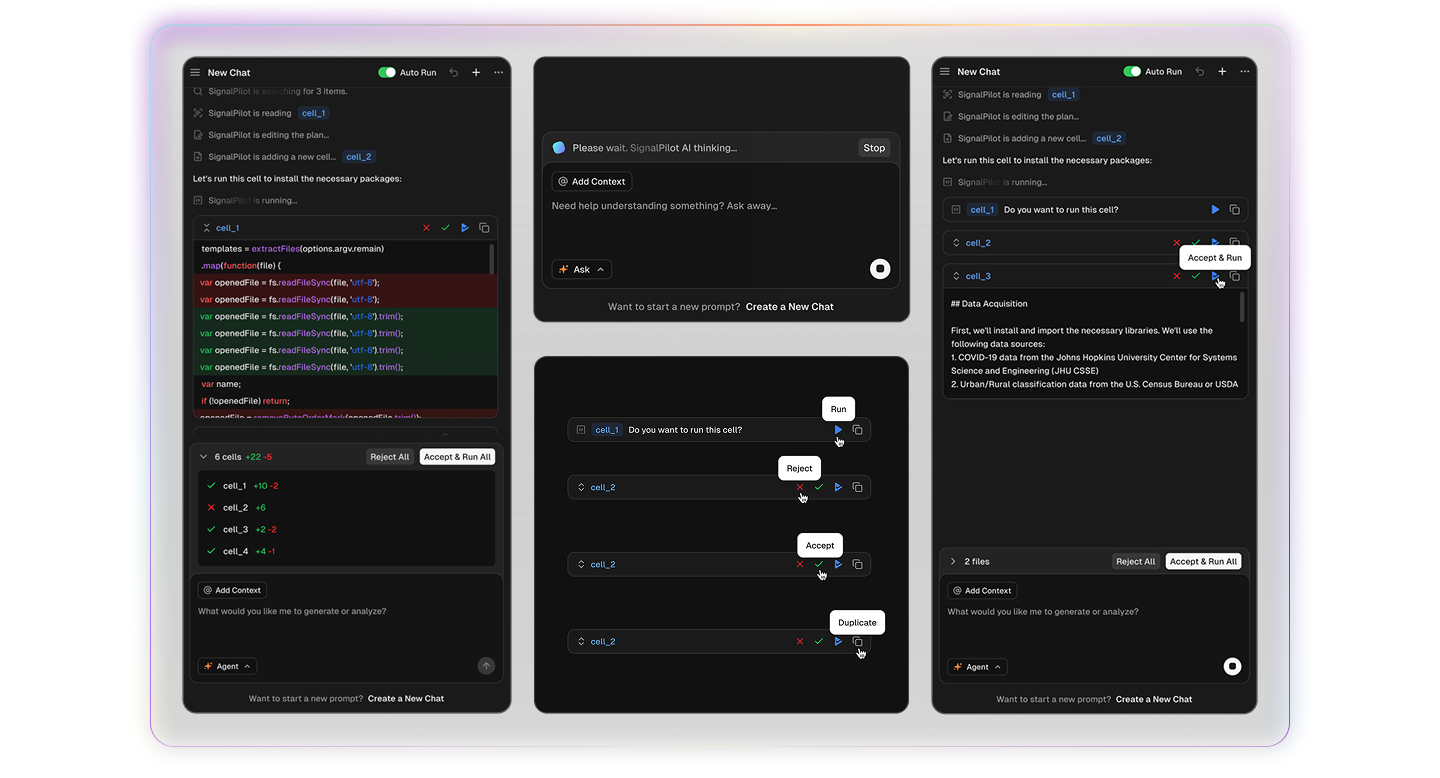
What You Can Do in SignalPilot

Uses your real db schemas, models, helpers.

Shows a clear, multi-step plan with transparent assumptions before touching your notebook
Turns raw tables into instantly sharable plots, models, and summaries

Helps small teams ship 10× more analysis without switching tools

Aligns AI with your naming, modules, and Rules—so output feels native to your workspace

Learns from your notebook history to suggest context-aware next steps
Safe for Production Data
Not just demo datasets. Use SignalPilot confidently with real production data.

Local & VPC Deployment
Run SignalPilot locally or inside your VPC
No data leaves your environment by default
Complete control over your data infrastructure

Bring Your Own LLM
Connect to Anthropic, OpenAI, or local open-weights models
Support for on-prem HuggingFace deployments
Stateless, zero-retention options available

Granular Data Controls
Per-notebook controls over which dataframes the model can see
Built-in redaction and sampling for sensitive data
Full audit logs of all model-visible data
Safe to use on real production data, not just demo datasets.
Why SignalPilot Beats Other AI Tools
| Product | Content Awareness | Content Editing | Error Handling | Deployment Options | Primary Use Case |
|---|---|---|---|---|---|
Inspects DF shapes, dtypes, NaNs | Notebook-native edits w/ diff + review | Error + schema change recovery | Private / VPC deploy | Built for quant & DS workflows | |
Limited inline context | May insert code fragments only | Blind to downstream breakage | Cloud-tethered | General coding | |
Has no real data context | Dumps pseudo-code | Hallucinates results | Cloud-tethered | General chat |
Who It's For
Built for data professionals who need AI that understands their actual work context
Data scientists
Handle more product and growth questions straight from the warehouse and notebooks—without constantly rewiring SQL and Python when schemas or dbt models change.
ML engineers
Ship models and experiments faster by having SignalPilot plan feature pipelines, call real repo helpers, and write training/eval code that runs in your environment.
Scientific & policy research
Spend more time on models, papers, and client work—and less time wiring panel, geospatial, or macro data and rebuilding plots for every revision.
Quant & trading research
Iterate on signals, risk, and backtests using real internal data and helpers instead of fragile, hand-written glue code or invented backtest utilities.
Product & growth engineers
Connect product analytics, event streams, and internal tables in notebooks so you can quickly test features, measure impact, and answer "did this actually move the needle?"
Technical founders
Prototype data products and internal tools with an AI copilot that understands your repo, warehouse, and notebook state—so you can go from idea to working analysis fast.
We built SignalPilot because we were tired of debugging AI code that never saw our real stack.