SignalPilot ADE-Bench Report: 96.9%, Highest Score Ever
Tarik Moon
What is ADE-Bench?
ADE-Bench is a public benchmark from dbt Labs that measures how well AI agents handle real-world analytics engineering tasks. Think of it as a standardized test for data AI: each task drops the agent into a real project and says “fix this” or “build this.”
Unlike toy benchmarks, ADE-Bench operates inside existing codebases with real dependencies, pre-built models, and the kind of messiness data teams deal with daily. Tasks span 9 domains with 258+ integration tests, and a task only passes when 100% of its tests pass, with no partial credit.
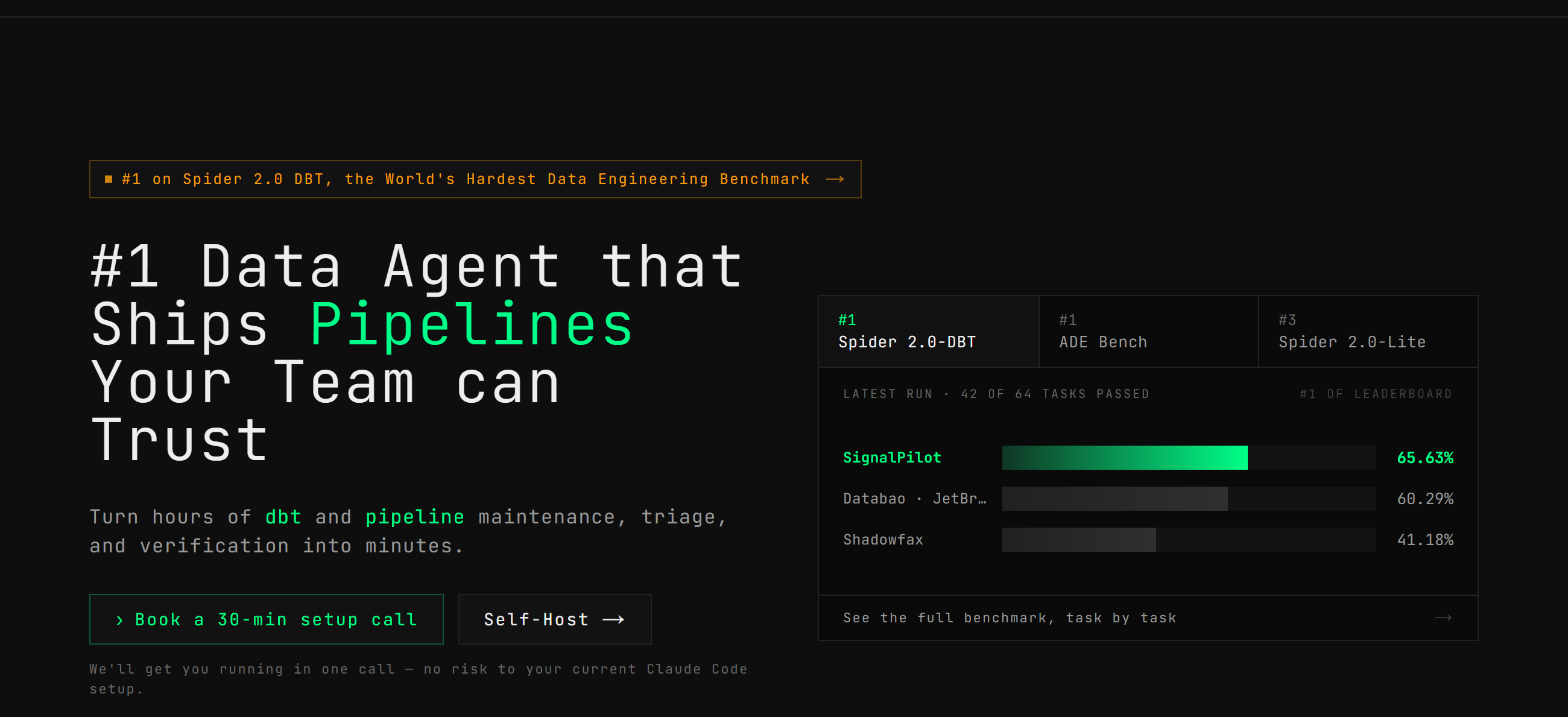
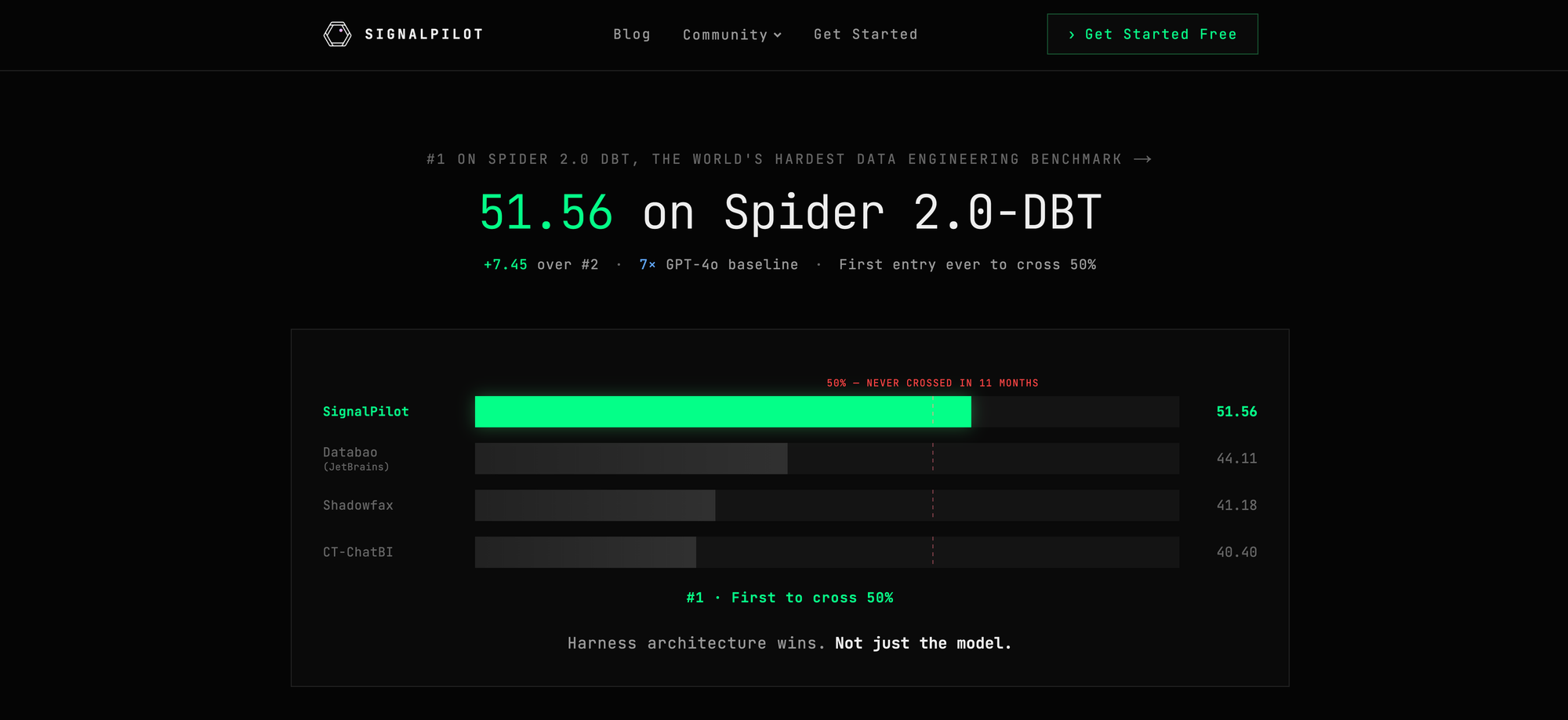
The Unofficial Leaderboard
We ran SignalPilot on all 64 ADE-Bench tasks, the only system to report on the full benchmark. Here’s how we compare on the 43-task subset that other systems report on:
Results by Domain
Every other task passes. Two tasks (f1008 andworkday001) are structurally unresolvable by any system.
Selects snapshot strategy correctly when updated_at is frozen. Writes unit tests with edge-case coverage.
Follows YML contracts precisely. Uses native dbt model versioning instead of standalone _v2 files.
Preserves driving table when extracting CTEs. Never drops entities with zero activity.
Distinguishes cumulative from per-event columns. Matches sibling model patterns. 1 unresolvable task (f1008).
Largest domain (17 tasks). Surgical filter scoping, enum discovery from source data, Jinja cleanup.
Identifies correct driving table when source tables have disjoint key sets, the task others called a bug.
Finds and fixes the same pattern across all sibling staging models, not just the first match.
Basic dbt transformations. Baseline tasks verifying agent can run dbt and produce correct output.
workday001 has no real prompt, no expected output, and a placeholder seed. Unresolvable by any system.
Why 2 of 64 Are Impossible
f1008F1Solution seed is a placeholder (foo). No expected output to validate against.
workday001WorkdayNo real prompt, no expected output, placeholder seed (foo). The task instructs the agent to do nothing.
Tasks others blamed on the benchmark
Other agents’ reports list several unresolved tasks, attributing some to benchmark quality rather than agent limitations. SignalPilot passes all of them.
f1006“Logic error using SUM instead of MAX”
Distinguish cumulative columns (MAX for final) from per-event columns (SUM)
intercom003“Data type overflow bug in answer key”
Select the correct driving table when source tables have disjoint keys
How SignalPilot Works
SignalPilot is an open-source MCP server and Claude Code plugin that sits between the AI agent and your database. It provides specialized tools, domain knowledge, and automated verification, so the agent can’t guess at column names, silently inflate metrics, or try to delete your data.
Schema exploration, SQL validation, query execution, all with DDL/DML blocking and audit logging
Conditional knowledge loading based on the task: ecommerce, financial, HR, marketing, and dbt-specific skills
Project scan, mapping, validation, macro discovery, research, technical spec, SQL writing, verification
Model existence, column schema, row count, fan-out detection, cardinality audit, value spot-check, table names
On ADE-Bench, the agent runs with a governed MCP server (DDL/DML blocking, LIMIT injection, audit logging), skill-based workflow (8-step lifecycle), domain-specific skills (loaded conditionally per task), and a verifier agent (7-check protocol after every build).
From 71% to 96.9%
Our starting point was the SignalPilot agent that scored #1 on Spider 2.0-DBT (65.63%, +5.34 over #2). That agent already scored 71% on its initial ADE-Bench run. The gap wasn’t reasoning ability; it was missing knowledge about newer dbt features the agent had never encountered.
dbt-snapshotsStrategy selection, column casing, SCD2 verification
dbt-testingunit_tests YAML format, given/expect blocks, edge cases
dbt-versioningversions: config for model versioning
Plus one system prompt rule: Trust the YML contract for output shape. Do not add, remove, or rename structural elements.
ADE-Bench vs Spider 2.0-DBT
ADE-Bench and Spider 2.0-DBT test fundamentally different things. Understanding the difference matters when you’re evaluating which AI agent will actually work on your project.
Tasks tell the agent exactly what to do. The codebase is clean, the YML is accurate, and instructions are explicit.
“Fix this error: dbt_utils.surrogate_key has been replaced by dbt_utils.generate_surrogate_key...”
Tasks describe a business outcome. The agent must explore the schema, reason about business logic, and derive SQL from incomplete docs.
“Aggregate user reviews by sentiment on a daily and month-over-month basis, while combining listings and host info...”
ADE-Bench prompts are imperative: “fix this error,” “create these models,” “remove this variable.” The codebase is clean, the YML is accurate, and the project structure tells the agent what to do. The challenge is following instructions precisely and knowing your dbt features.
Spider 2.0-DBT prompts are descriptive: “aggregate these metrics,” “create this view.” The agent must explore the schema, understand business logic, query the data to discover grain and cardinality, and derive correct SQL from documentation that is often wrong. The challenge is reasoning under uncertainty.
This is why our ADE-Bench score jumped from 71% to 97% by adding three skills and one sentence. The benchmark tests feature knowledge, not reasoning depth. Our Spider 2.0-DBT score (#1 at 65.63%) required months of prompt engineering, verification agents, and domain skills because that benchmark tests whether the agent can actually think.
Both benchmarks matter. But if you’re evaluating which AI agent will perform best on your messy, real-world dbt project, look at Spider 2.0-DBT scores, not ADE-Bench scores.
What We Learned
ADE-Bench was great for discovering gaps in dbt feature coverage. Snapshots, unit tests, and model versioning were all features we hadn’t taught SignalPilot about, and filling those gaps had an outsized impact.
But ADE-Bench didn’t test the things that make real-world data work hard: ambiguous prompts, incorrect documentation, and messy schemas. The tasks assume clean codebases, accurate YML contracts, and well-structured projects. Real-world data work is messier than that.
We prefer Spider 2.0-DBT for its much harder nature and the reasoning traces required to pass it. ADE-Bench tests feature knowledge and instruction-following in ideal codebases. Spider 2.0-DBT tests whether the agent can think through a data problem when the documentation is wrong and the only truth is in the data itself.
Three tasks we fixed upstream
Three tasks (f1002,analytics_engineering004, andanalytics_engineering006) can’t be solved from project context alone: their gold solutions hinge on column names and aliases that never appear in any file, schema, or naming convention left in the workspace.
Rather than leak those answers into the agent’s prompt, we fixed the benchmark itself and opened PR #151 to the official ADE-Bench repo. The full reasoning and exact changes are in the PR.